Dishire 구현 방식 (How it Works)
이 페이지는 Dishire 프로토타입이 내부적으로 어떻게 동작하는지, 어떤 구조와 흐름으로 LLM을 사용했는지를 기술적인 관점에서 정리한 섹션입니다.
1. 시스템 개요 및 전제
Dishire 프로토타입은 사용자가 입력한 상황, 활용 가능한 재료, 기본적인 선호 정보를 LLM에 전달하여 한 끼 레시피를 생성하는 간단한 웹 기반 실험 프로젝트입니다. 전체 구조는 프론트엔드(React), API 서버(FastAPI), 그리고 외부 LLM API(OpenAI)의 세 계층으로 이루어져 있으며, 특정 기술이나 기업 내부 인프라에 의존하지 않는 범용적인 구성으로 설계되었습니다.
레시피 생성 과정은 단일 프롬프트 호출 방식이 아닌, 생성 요소를 단계별로 분리해 요청하는 흐름을 실험해보는 것을 목표로 했습니다. 이는 응답 시간, 토큰 사용량, 추천 과정의 제어 가능성 등을 비교해보기 위한 프로토타입 수준의 구조적 실험이었습니다.
이 페이지에서는 구현 세부 코드나 특정 회사 자산을 포함하지 않고, 서비스를 어떤 흐름과 구조로 구성했는지에 대한 개념적 관점에서만 설명합니다. 기술 요소와 프롬프트 구조는 모두 일반적인 웹 서비스 및 LLM 사용 패턴을 기반으로 재구성한 내용입니다.
2. 전체 시스템 아키텍처
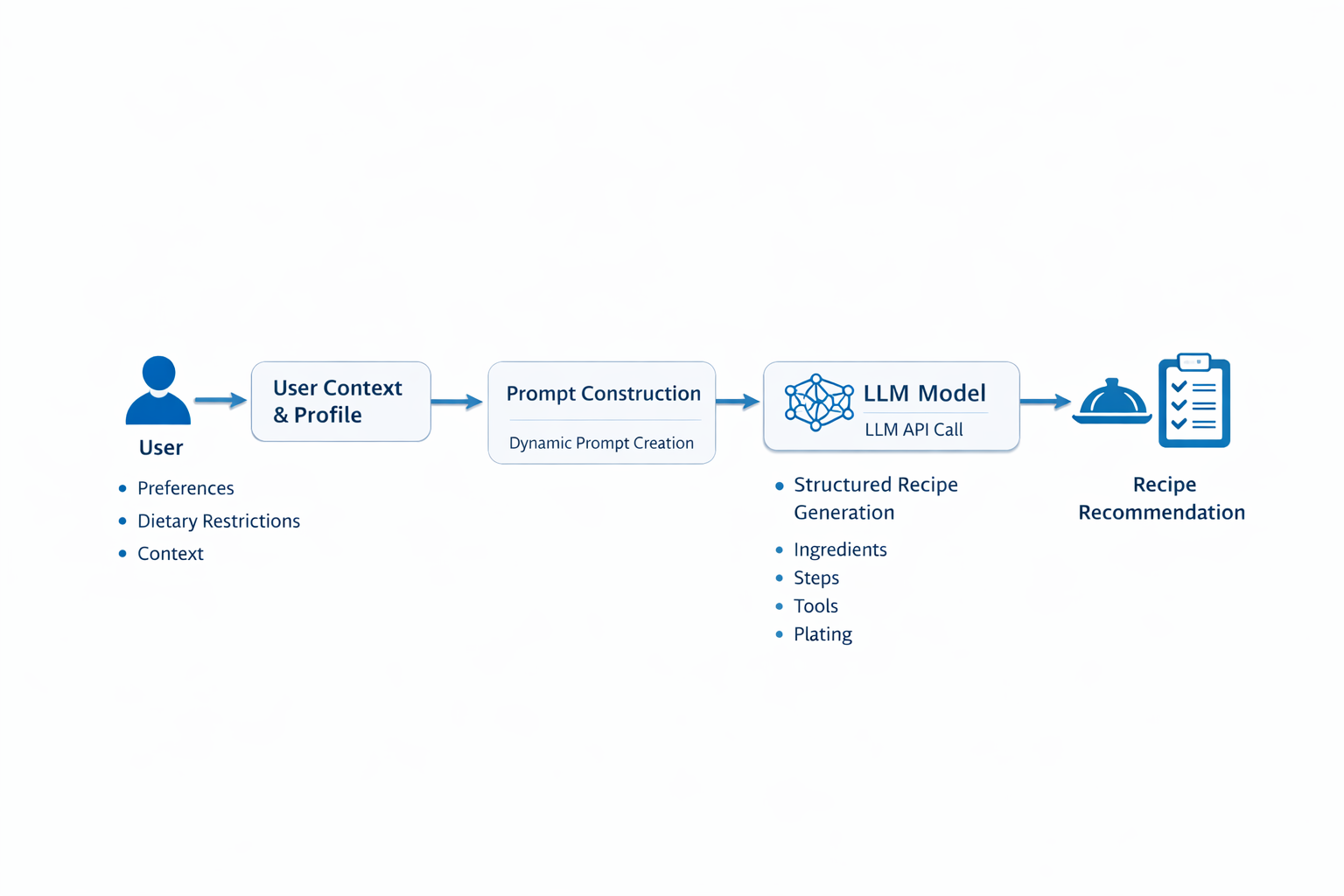
Dishire 프로토타입은 크게 네 부분으로 나눌 수 있는, 단순한 웹 서비스 구조를 가지고 있습니다. ① React 기반 웹 UI, ② FastAPI 기반 백엔드 API 서버, ③ 외부 LLM API(OpenAI), ④ 선택적인 데이터베이스 계층(PostgreSQL)으로 구성되어 있으며, 특정 기업 인프라에 종속되지 않는 일반적인 아키텍처를 따릅니다.
-
프론트엔드 (React)
사용자가 상황, 재료, 기본 선호 정보를 입력하고, 추천 방식을 선택하는 화면을 제공합니다. 입력된 값은 REST API 요청(HTTP POST) 형태로 백엔드에 전달되며, LLM에서 생성된 레시피를 카드 형태의 UI로 보여주는 역할을 담당합니다. -
백엔드 API 서버 (FastAPI)
프론트엔드로부터 JSON 요청을 받아, 선택된 추천 유형과 사용자 프로필 정보를 조합해 프롬프트를 구성한 뒤 LLM API를 호출합니다. LLM 응답으로 받은 텍스트를 제목, 재료, 도구, 조리 단계, 팁과 같은 필드로 분리·가공하여 다시 JSON 형식으로 프론트엔드에 반환합니다. -
LLM 호출 계층 (OpenAI API)
백엔드에서 생성한 프롬프트를 전달받아 레시피 초안을 생성하는 역할을 합니다. 별도의 파인튜닝 모델을 사용하기보다는, 프롬프트 설계와 호출 흐름을 조정하는 방식으로 응답 품질과 제어 가능성을 실험한 구조입니다. -
데이터베이스 (PostgreSQL, 프로토타입 수준)
사용자 계정과 기본 프로필(예: 식단 제한, 알레르기, 종교적 식습관 등)처럼 레시피 추천에 반복적으로 사용되는 최소한의 정보를 저장하는 용도로 설계했습니다. 프로토타입 단계에서는 복잡한 로그 분석이나 대규모 데이터 처리가 아니라, “향후 개인화 추천으로 확장할 수 있는 여지”를 두는 수준에서만 활용했습니다.
정리하면 Dishire는 “사용자 입력 → API 서버 → LLM 호출 → 구조화된 레시피 응답 → UI 표시”라는 단순한 파이프라인을 바탕으로, LLM을 어떻게 서비스 흐름에 연결할지 검증해보기 위한 프로토타입 아키텍처라고 볼 수 있습니다.
3. 레시피 생성 플로우 (요청 → LLM 단계 호출 → 응답)
Dishire의 백엔드는 단일 프롬프트 호출이 아니라, 여러 LLM 호출을 순차적으로 조합해 하나의 레시피를 완성하는 구조로 구성되어 있습니다. 첫 요청에서 기본 뼈대를 생성하고, 이후 생성 단계는 동일한 세션 정보를 재사용하는 방식으로 설계되어 레시피의 일관성과 연결성을 유지하는 데 초점을 맞추었습니다.
① 초기 요청 처리
사용자가 추천 버튼을 누르면 상황·재료·선호 정보가 JSON 형태로 전송되며, 백엔드는 이를 바탕으로 1차 생성에 필요한 기본 프롬프트를 구성합니다. 이 단계에서는 레시피의 방향성을 결정하는 핵심 정보(요리 제목, 간단 설명, 난이도, 기본 컨셉)를 생성합니다.
② 세션 캐시 저장
최초 생성이 완료되면, 백엔드는 언어 정보, 사용자 입력 맥락, 1차 생성 결과, 내부 프롬프트 상태를 세션 캐시에 저장합니다. 이후 단계들은 모두 이 세션 데이터를 기반으로 이어지기 때문에, 여러 호출을 거치더라도 레시피의 일관성이 유지됩니다.
③ 단계별 생성 요청
이후 프론트엔드에서 요청하는 단계(예: 재료 생성, 보조정보 생성 등)에 따라, 백엔드는 캐시된 상태를 불러와 새로운 프롬프트를 구성한 뒤 LLM에 전달합니다. 각 단계는 서로 독립적으로 설계되었지만, 동일한 세션 정보를 공유함으로써 레시피 전반의 톤과 맥락이 연결되도록 했습니다.
④ 최종 응답 구조화
LLM에서 생성된 텍스트는 백엔드에서 다시 title, description, ingredients, steps, tips 같은 명확한 JSON 필드로 분리해 정리합니다. 이 구조화된 응답은 React UI에서 레시피 카드 형식으로 표시됩니다.
전체적으로 Dishire는 “초기 생성 → 세션 유지 → 단계별 보강 → 구조화 응답” 흐름을 통해, 단순 단일 프롬프트 기반 생성보다 제어 가능한 형태의 레시피 생성을 실험하는 데 초점을 맞춘 구조입니다.
4. 다단계 생성 구조와 단계별 역할
Dishire의 내부 구현에서는 단계별로 LLM을 호출하는 multi-step 구조를 사용했습니다. 코드상으로는 parallel → validate → detail의 세 단계 흐름으로 구성되어 있지만, detail 내부가 여러 하위 생성 과정으로 이루어져 있어, 개념적으로는 이를 네 가지 역할 단계로 구분할 수 있습니다.
1) 1차 생성 — 요리 방향성 설정
첫 단계에서는 제목, 간단 설명, 난이도, 소요 시간 등 레시피의 상위 개념을 생성합니다. 이후 단계에서 일관성을 유지하기 위한 기반 정보이므로 세션 캐시에 저장됩니다.
2) 2차 생성 — 보조 생성 단계 (Parallel)
초기 생성 결과와 동일한 맥락을 유지하면서 일부 요소를 다시 생성하거나 변형해보는 보조 생성 단계입니다. 여러 후보를 제공하는 기능이라기보다는, 레시피의 밸런스를 보완하거나 다양성을 확보하기 위한 실험적 생성 흐름입니다.
3) 3차 생성 — 검증 단계 (Validate, 프로토타입 수준)
구조적으로는 생성된 요소를 점검하거나 보정하기 위한 검증 단계가 포함되어 있습니다. 다만 프로토타입 단계에서는 이 로직이 단순화되어 적용되었으며, 응답 검증 기능은 향후 확장 가능성을 고려한 skeleton 형태로만 구성되었습니다. 이 단계는 multi-step 파이프라인의 확장성과 품질 관리 실험을 위한 기반이었습니다.
4) 4차 생성 — 상세 보강 단계 (Detail)
마지막 단계에서는 재료 → 도구 → 조리 과정 → 팁 → 보관 → How to eat 등에 해당하는 구체적인 세부 요소들을 생성합니다. detail 내부가 여러 하위 요청으로 구성되어 있어, 레시피 전체의 흐름과 맥락을 자연스럽게 맞추기 위한 역할을 합니다.
정리하면 Dishire의 생성 구조는 “기본 생성 → 보조 생성 → 검증(프로토타입) → 상세 보강” 의 multi-step 흐름을 갖고 있으며, 세션 기반으로 전체 맥락을 공유해 최종 레시피의 일관성을 유지하도록 설계되었습니다.
5. 프롬프트 템플릿 설계 방식
Dishire의 프롬프트 구조는 단순한 자연어 요청이 아니라, 정적 템플릿(static prompt)과 동적 입력(dynamic injection)을 조합하는 형태로 설계되었습니다. 이는 레시피 도메인의 특성(출력 형식·항목 구조·제약조건이 명확함)을 고려하여, 응답의 일관성과 재현성을 최대한 확보하기 위한 선택이었습니다.
1) 정적 템플릿: 출력 형식과 공통 제약을 고정화
정적 템플릿은 모든 요청에서 변하지 않는 고정 구조이며, LLM이 어떤 형태로 응답해야 하는지를 명확히 안내하기 위한 영역입니다. 다음과 같은 요소들로 구성됩니다.
- 모델 역할 지정(예: “당신은 레시피 생성 보조 셰프입니다.”)
- 고정된 출력 포맷(제목 → 설명 → 재료 → 도구 → 조리 단계 → 팁)
- 항상 적용되는 제약조건 블록(알레르기, 식단 제한, 종교적 규칙 등)
이 구조는 출력 형식 제어와 후처리(파싱) 안정성을 위해 필수적인 기반이었습니다. 레시피처럼 구조화된 응답이 필요한 경우 정적 템플릿이 특히 유효했습니다.
2) 동적 입력: 사용자 상황·재료·제약조건 삽입
동적 입력(dynamic injection)은 각 요청마다 달라지는 사용자 정보가 들어가는 영역입니다.
템플릿 내에 {situation}, {ingredients},
{diet_rules}와 같은 placeholder를 두고,
해당 요청 시점의 데이터를 주입하는 방식으로 구성했습니다.
이 방식은 완전한 free-form prompting이 아니라, “정적 구조 위에 필요한 값만 채워 넣는 partially dynamic prompt”에 해당합니다. 구조는 고정되되, 사용자 조건만 바뀌므로 안정성과 개인화 사이에서 균형을 맞출 수 있었습니다.
3) 추천 유형별 템플릿 변형
정석 추천, 재료 기반 추천, 상황 기반 추천과 같은 추천 방식은 모두 공통 템플릿을 사용하지만, 동적 입력에 서로 다른 정보를 우선적으로 주입하는 방식으로 차별화했습니다.
- 정석 추천: 상황·기분·식단 제한을 중심으로 구성
- 재료 기반 추천: 재료 목록을 핵심 정보로 강조
- 상황 기반 추천: 시간, 난이도, 건강 목표 등 조건을 우선 반영
템플릿 자체가 바뀌지 않기 때문에 유지보수 비용이 낮고, 프롬프트 실험을 할 때도 동일한 구조 내에서 변수를 조절할 수 있어 효율적이었습니다.
4) 단계별 생성과 프롬프트 연계
multi-step 생성 구조와 연계하여, 각 생성 단계는 서로 다른 템플릿 조합을 사용했습니다.
- 1차 생성 — 레시피의 기본 방향(제목/설명/난이도)
- Parallel 단계 — 동일한 컨텍스트를 기반으로 보조적 정보 생성
- Validate 단계 — skeleton 수준의 검증 단계(향후 품질 보정 확장 여지)
- Detail 단계 — 재료, 도구, 조리 과정, 팁 등 구체 요소 생성
각 단계는 이전 단계의 출력 일부를 다시 프롬프트에 포함하여 호출되기 때문에, 여러 번 호출하더라도 레시피의 맥락이 자연스럽게 이어지도록 설계되었습니다.
5) 장점과 한계
정적/동적 템플릿 조합은 도메인 특성상 안정적인 응답을 얻는 데 유리했으며, 단계별 생성 구조와 결합할 때 프롬프트 관리가 용이했습니다. 다만 완전한 동적 프롬프트에 비해 유연성은 제한적이며, 토큰 비용이나 응답 속도 측면에서의 최적화는 향후 더 실험이 필요한 부분입니다.
6. 데이터 구조 (사용자 프로필 · 요청 파라미터)
Dishire 프로토타입에서는 대규모 사용자 데이터를 다루지는 않았지만, 레시피 추천 품질에 직접적으로 관여하는 정보를 구조적으로 전달하기 위해 요청 파라미터(request payload) 구조와 기본 사용자 프로필(user profile)을 분리하여 설계했습니다. 이는 LLM 호출 시 필요한 정보만 명확하게 전달하고, 각 단계별 프롬프트 구성에 일관성을 확보하기 위한 구조적 선택이었습니다.
1) 사용자 프로필 구조
사용자 프로필은 레시피 생성 시 항상 고려되어야 하는 장기적·고정적 특성들을 담는 영역입니다. Dishire 프로토타입에서는 다음과 같은 필드를 갖는 단순한 구조로 구성했습니다.
- diet_type: 비건, 베지테리언, 저탄고지 등 식단 유형
- allergy: 견과류, 갑각류 등 알레르기 정보
- religious_restrictions: 돼지고기 회피 등 종교적 식습관
- flavor_preferences (선택): 선호 맛(매운맛, 감칠맛 등)
이러한 정보는 데이터베이스에 저장된 후, 모든 LLM 호출 프롬프트의 정적 제약 블록에 포함되는 형태로 사용되었습니다.
2) 요청 파라미터 구조
프론트엔드에서 백엔드로 전달되는 요청(request payload)은 상황 기반 정보와 즉시성 정보를 주로 다룹니다. 이는 각 레시피 요청마다 달라질 수 있는 값들입니다.
- situation: 현재 상태(피곤함, 간단히 먹고 싶음, 위로받고 싶음 등)
- ingredients: 사용 가능한 재료 목록
- constraints: “빠르게 먹고 싶다”, “10분 안에” 등 조건
- type: 추천 방식(정석, 재료 기반, 상황 기반)
요청 파라미터는 정적 템플릿의 동적 영역에 삽입되며, 1차 생성뿐 아니라 parallel, validate, detail 단계에서도 일관된 구조로 전달됩니다.
3) 세션 저장 구조(Session Cache)
multi-step LLM 호출 구조를 유지하기 위해, 첫 생성 단계에서 나온 결과와 입력 정보를 세션 단위로 저장했습니다. 저장된 정보는 이후 단계(detail 등)에서 동일하게 재사용되어, 여러 번의 LLM 호출에도 맥락이 유지되고 레시피 품질이 흔들리지 않도록 했습니다.
- context: 첫 단계에서 생성된 기본 방향(제목, 설명 등)
- prompts: 해당 요청에 사용된 프롬프트 기록
- user_profile: 정적 제약조건
- situation / ingredients: 요청별 즉시성 정보
- language: 출력 언어 정보
세션 기반 설계는 여러 단계로 나뉜 생성 과정에서도 레시피의 톤·재료·난이도가 일정하게 유지되는 데 도움이 되었으며, 추후 long-term personalization 기능을 확장할 수 있는 구조적 기반이 되었습니다.
7. LLM 호출 전략과 제약사항
Dishire는 레시피를 단일 프롬프트로 생성할 수도 있었지만, 프로토타입 단계에서는 multi-step LLM 호출 구조를 적용했습니다. 이는 레시피 도메인의 특성(여러 구성 요소·명확한 항목 구조)과 생성 품질 제어 문제를 해결하기 위한 실험적 접근이었습니다.
1) 왜 단일 호출 대신 여러 단계로 나누었는가
레시피는 제목·설명·재료·도구·손질 단계·조리 단계·팁 등 여러 구성 요소로 이루어져 있어, 단일 프롬프트로 한 번에 생성할 경우 결과는 일관적이지만 다음과 같은 실용적 문제가 있었습니다.
- 사용자 경험 측면 — 처음부터 긴 레시피를 모두 보여주면 사용자가 선택 여부를 판단하기 어려움. 먼저 요리 방향(제목·간단 설명·난이도)만 빠르게 확인할 수 있는 흐름이 필요했습니다.
- 비용·응답시간 측면 — 전체 레시피를 한꺼번에 생성하면 불필요하게 많은 토큰을 사용하게 되고, 응답 시간이 길어질 수 있습니다.
- 구조적 일관성 문제 — 단일 호출에서는 “재료 목록에 없는 재료가 조리 단계에서 등장”하거나 “도구와 과정이 맞지 않는 경우” 등 구성 요소 간 불일치가 더 자주 발생했습니다.
- 세부 제어 한계 — 단일 호출은 하나의 덩어리로 결과가 나오기 때문에, 특정 단계(재료, 도구, 조리 과정 등)를 개별적으로 수정하거나 보완하기 어렵습니다.
이러한 문제를 해결하기 위해, Dishire는 “요리 방향 → 재료/도구 → 손질/조리 단계 → 팁/부가 정보” 처럼 의미 단위별로 LLM을 호출하는 구조를 실험했습니다. 각 단계에서 필요한 정보만 전달할 수 있어 토큰 낭비를 줄일 수 있었고, 생성된 요소들을 단계별로 검토하거나 보완하기 쉬워지는 장점이 있었습니다.
다만 이러한 설계적 기대와는 별개로, 실제 프로토타입 단계에서 multi-step 구조가 비용이나 품질 측면에서 단일 호출보다 우월하다고 단정할 수 있는지는 별도로 확인이 필요했습니다. 아래에서는 이러한 구조를 실제로 적용했을 때 관찰된 트레이드오프를 정리합니다.
2) 응답 시간과 토큰 사용량 관찰
multi-step 구조가 비용 또는 속도 측면에서 단일 호출보다 우월하다는 근거는 프로토타입 단계에서는 확인되지 않았습니다. Dishire의 요청 단위가 상대적으로 작았기 때문에, 토큰 사용량과 응답 시간은 단일 호출과 큰 차이가 없었고, 단계 수가 늘어나면 호출 횟수가 증가하는 trade-off도 존재했습니다.
- 토큰 사용량은 단일 호출 대비 유사하거나 가끔은 증가하기도 했음
- 여러 단계로 나누었다고 해서 응답 시간이 단축되지는 않음
- 레시피 품질도 일부 케이스에서는 단일 호출이 더 자연스럽게 나오기도 함
즉, multi-step 구조는 비용 최적화보다는 출력 형식의 안정성, 구성 요소별 제어, 레시피 구조화를 위한 실험적 접근이었습니다.
3) 품질 관리 측면의 한계
- Validate 단계는 skeleton 형태로만 존재하여, 실제 품질 보정 기능은 구현되지 못함
- Parallel 단계도 보조 생성 역할에 그쳤고, 생성 결과를 평가·선택하는 로직은 부재함
- 각 단계의 출력 품질을 정량적으로 측정·비교하는 실험은 충분히 수행하지 못함
- 대규모 사용자 로그 기반 자동 최적화나 피드백 루프는 구현 단계에 도달하지 못함
그럼에도 불구하고 multi-step 구조를 설계하고 실험해본 과정은, LLM 기반 레시피 시스템에서 어떤 지점이 제어 포인트가 되는지, 그리고 단일 호출과 multi-step 구조 간의 trade-off를 이해하는 데 중요한 인사이트를 제공했습니다.
4) 전체 요약
Dishire의 LLM 호출 전략은 성능(토큰·속도) 최적화보다는 출력 형식 통제, 단계별 품질 분리, 세션 기반 일관성 유지를 우선한 프로토타입 실험이었습니다. 단일 호출이 더 자연스러운 경우도 있었지만, multi-step 구조는 레시피를 기능 단위로 분해하고 제어하는 실험적 설계의 기반이 되었으며, 향후 프롬프트 자동화·모델 평가·개인화 엔진 확장과 같은 방향으로 발전할 수 있는 여지를 만들어 주었습니다.